Оперативная память: история развития и принципы работы

Прежде чем мы начнем говорить непосредственно об оперативной памяти, ее развитии и типах, следует разобраться, для чего она предназначена и зачем входит в состав современных компьютеров.
Специалисты, исследующие историю развития вычислительной техники, считают первой вехой на тернистом пути возникновения и развития компьютеров разработку британцем Чарльзом Бэббиджем аналитической машины в Лондоне в далеком 1834 году. Из-за проблем с финансированием и отсутствием необходимых для постройки машины технологий построить ее в то время так и не удалось. Несмотря на этот факт, именно аналитическую машину считают первым созданным человеческим разумом автоматическим устройством для хранения и обработки математической информации, то есть первым компьютером.

Один из элементов аналитической машины, собранный сыном Бэббиджа после его смерти (фото Andrew Dunn)
Совокупность основных узлов и элементов, входящих в состав аналитической машины (и современных компьютеров также), называют архитектурой вычислительной машины. Бэббидж при разработке своего устройства выделил несколько основных частей. Первая — это «мельница», которая занималась обработкой информации (аналог современного процессора). Вторая — устройства ввода-вывода, с помощью которых вводились данные для обработки и с которых снимался затем результат. Третья — «склад», в котором хранились промежуточные результаты вычислений. Четвертая — управляющий элемент, предназначенный для передачи данных между остальными узлами аналитической машины.
Подобную архитектуру имеют все современные компьютеры, состоящие из арифметико-логического устройства (АЛУ), шины передачи данных, оперативной памяти и устройств ввода-вывода. Упрощенно взаимодействие этих элементов можно изобразить с помощью следующей схемы.
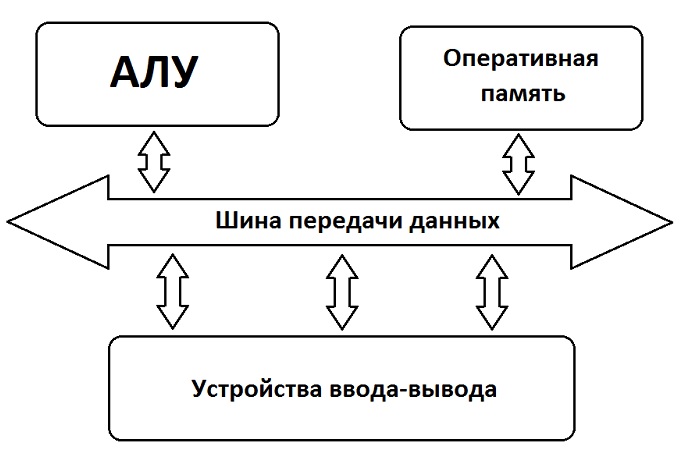
Назначение всех элементов точно соответствует назначению узлов аналитической машины Бэббиджа. Оперативная память, подобно «складу» в машине британца, отвечает за временное хранение информации, которая содержит входящие, выходящие и промежуточные данные, а также программы и алгоритмы, с помощью которых они обрабатываются.
В информатике оперативную память принято также называть оперативным запоминающим устройством (ОЗУ), что более точно отображает суть этого элемента вычислительной машины.
Физическая реализация ОЗУ на разных этапах развития
В машине Бэббиджа для оперативного хранения информации предусматривался сложный массив валов и шестерен, положение которых и соответствовало тому или иному значению информационной единицы. Подобный подход с небольшими изменениями просуществовал довольно долго, пока вычислительные машины представляли собой чисто механические устройства.
Появление электромеханических вычислителей и первых электронно-вычислительных машин (ЭВМ) привело к созданию более быстрых и надежных методов хранения информации. На первых порах различные исследовательские центры весьма широко экспериментировали с конструкциями и физическими принципами работы запоминающих устройств. Были созданы ОЗУ, работающие на электромеханических реле, на электромагнитных переключателях, на электростатических трубках, на электронно-лучевых трубках. Затем появились различные варианты магнитных запоминающих устройств — магнитные диски и барабаны, в то время как длительное хранение информации осуществлялось на магнитных лентах. Диски и барабаны обеспечивали значительно меньшее время доступа к каждой ячейке данных по сравнению с лентами. А одним из основных требований, предъявляемых к оперативной памяти, было и остается по сей день высокое быстродействие.

Помимо магнитных дисков и барабанов длительное время в качестве быстрой памяти использовались массивы на ферромагнитных сердечниках, которые обеспечивали очень высокую скорость доступа. Основным недостатком подобных массивов была большая энергоемкость и весьма крупные габаритные размеры ОЗУ.
Элемент памяти на магнитных сердечниках конструкции К. Олсена (1964 г.)
Как видим, основными тенденциями при разработке новых типов памяти были и остаются постепенная миниатюризация элементов памяти, что необходимо для увеличения емкости хранимой информации, снижение энергопотребления и увеличение быстродействия каждой ячейки и модулей памяти в целом.
Самый серьезный толчок развитию ЭВМ дало создание БИС (больших интегральных схем), состоящих из большого числа полупроводниковых транзисторов, заключенных в один корпус. Скорость обработки информации увеличилась настолько, что быстродействия существовавшей на то время оперативной памяти катастрофически не хватало для обеспечения нормальной работы компьютеров в целом. Понадобилось разработать принципиально новые методы хранения информации, которыми мы пользуемся и до сих пор.
Строение и принцип работы современной оперативной памяти
В современных микросхемах памяти наиболее широко используются два метода хранения информации. Первый основан на широко известном свойстве конденсатора сохранять накопленный заряд достаточно продолжительное время, чтобы его можно было использовать для кратковременного хранения единицы информации. Второй подразумевает использование для хранения каждого бита информации единичного транзисторного триггера. Рассмотрим оба метода более подробно.
Запись информации в конденсаторную ячейку осуществляется путем заряда этого конденсатора до уровня, соответствующего логическому нулю или единице. Обеспечивает заряд до нужного уровня сопряженный с конденсатором транзистор, который открывается под воздействием управляющего сигнала. Получается, что каждая ячейка хранения бита информации является парой транзистор плюс конденсатор.
Принципиальная схема ячейки динамической памяти
Основное достоинство — дешевизна производства и малый размер каждой ячейки. Современная элементная база позволяет вмещать миллионы подобных пар на каждый квадратный миллиметр микросхемы памяти.
Основной недостаток подобного метода хранения информации является следствием физических свойств конденсаторов. Как известно, любой конденсатор, насколько бы досконально он ни был разработан и произведен, имеет такой неприятный параметр, как ток утечки. И относительная величина этого тока обратно пропорциональна геометрическим размерам элемента. Соответственно, время, за которое разряжается конденсатор, тем меньше, чем меньше сам конденсатор. В микросхемах памяти размеры каждого емкостного элемента исчисляются десятками нанометров, а время их саморазряда составляет миллисекунды. Вполне очевидно, что, для того чтобы информация, записанная в ячейку памяти, хранилась в течение времени, достаточном для ее обработки, ее необходимо обновлять с периодичностью, исключающей потерю от саморазряда конденсаторов. Поэтому в микросхемах памяти, основанных на конденсаторных ячейках, идет постоянный процесс обновления хранимой информации. Этот процесс называют регенерацией, и для его осуществления на модулях памяти предусмотрены специальные контроллеры.
Память подобного типа называют динамической. Процесс постоянной перезаписи приводит к увеличенному расходу энергии и дополнительному нагреву микросхем, а также к ухудшению такого важного параметра, как время отклика.
Еще одним неприятным свойством любого конденсатора является его электрическая инерционность. Изменение емкости не является мгновенным процессом, следовательно, чтение единицы информации и ее перезапись занимают какое-то время, необходимое для накопления или сброса электрического заряда.
В триггерных системах памяти хранение каждого бита информации происходит в единичных триггерах, которые фактически представляют собой группы из шести-восьми транзисторов. Так как состояние триггера зависит исключительно от наличия управляющего сигнала и не меняется с течением времени (пока есть питающее напряжение), то такой тип памяти называют статической памятью. Основным достоинством статической ОЗУ является ее чрезвычайно высокое быстродействие, так как переключение триггера происходит практически мгновенно при подаче соответствующего управляющего сигнала на вход элемента.
Недостатки также достаточно очевидны. Первый — значительно более высокая стоимость по сравнению с динамической памятью. Создать на пластинке кремния группу из полудюжины транзисторов значительно сложнее и дороже, чем пару конденсатор плюс транзистор.
Второй недостаток — значительно большие размеры каждой ячейки памяти, что ведет к существенному увеличению размеров каждой микросхемы памяти.
Вместо вывода
На сегодняшний день широко используются и статический, и динамический тип ОЗУ. На более дешевых динамических элементах построены обычные модули памяти, внешний вид которых знаком каждому, кто хоть раз видел раскрытый компьютер. Статическая память используется в первую очередь там, где высокое быстродействие важнее экономии в стоимости и размерах. Это прежде всего процессорная кеш-память. Скорость работы кеша во многом определяет и общую скорость работы современных процессоров, что и обуславливает применение более дорогого и более быстрого ОЗУ.
Отдельного упоминания заслуживает и еще одна особенность современной оперативной памяти — ее энергозависимость. И конденсаторные схемы, и триггеры хранят записанную в них информацию, пока не отключено питающее напряжение. Как только питание отключается, вся информация бесследно стирается. Это является основной причиной того, что любой компьютер после выключения длительное время занят запуском операционной системы, всех служб и резидентных программ. Уже достаточно длительное время в крупнейших исследовательских центрах идет разработка энергонезависимой оперативной памяти, которая будет хранить записанную в нее информацию длительное время и без подачи питающего напряжения. Работающие прототипы уже существуют, но пока еще слишком дороги и ненадежны для массового применения.
С каждым годом компьютеры становятся все мощнее, оперативная память становится все быстрее и надежнее. Увеличивается частота, на которой способны стабильно работать микросхемы ОЗУ, и стремительно растет объем памяти в каждой микросхеме. Каждый производитель старается хоть в чем-то опередить конкурентов, что приводит к бурному развитию элементной базы и росту числа типов и моделей модулей памяти, доступных на рынке сегодня.
В одной из следующих статей мы подробно рассмотрим современный рынок оперативной памяти, постараемся разобраться в основных типах оперативки и отдельно поговорим о крупнейших производителях микросхем и модулей памяти.
20.02.2014 Худяков Юрий
Оперативная память — из глубин времен до наших дней
Оперативная память персональных компьютеров сегодня, как и десять лет тому назад, строится на базе относительно недорогой динамической памяти — DRAM (Dynamic Random Access Memory). Множество поколений интерфейсной логики, соединяющей ядро памяти с «внешним миром», сменилось за это время. Эволюция носила ярко выраженный преемственный характер — каждое новое поколение памяти практически полностью наследовало архитектуру предыдущего, включая, в том числе, и свойственные ему ограничения. Ядро же памяти (за исключением совершенствования проектных норм таких, например, как степень интеграции) и вовсе не претерпевало никаких принципиальных изменений! Даже «революционный» Rambus Direct RDRAM ничего подлинного революционного в себе не содержит и хорошо вписывается в общее «генеалогическое» древо развития памяти.
Поэтому, устройство и принципы функционирования оперативной памяти лучше всего изучать, понимаясь от основания ствола дерева (т.е. самых древних моделей памяти) по его веткам вверх — к самым современным разработкам, которые только существуют на момент написания этой статьи.

Рисунок 1 Память: Миллиарды битовых ячеек, упакованных в крошечную керамическую пластинку, свободно умещающуюся на ладони.
Устройство и принципы функционирования оперативной памяти
В ядре
Ядро микросхемы динамической памяти состоит из множества ячеек, каждая из которых хранит всего один бит информации. На физическом уровне ячейки объединяются в прямоугольную матрицу, горизонтальные линейки которой называются строками (ROW), а вертикальные — столбцами (Column) или страницами (Page).
Линейки представляют собой обыкновенные проводники, на пересечении которых находится «сердце» ячейки — несложное устройство, состоящее из одного транзистора и одного конденсатора (см. рис. 2.4).
Конденсатору отводится роль непосредственного хранителя информации. Правда, хранит он очень немного — всего один бит. Отсутствие заряда на обкладках соответствует логическому нулю, а его наличие — логической единице. Транзистор же играет роль «ключа», удерживающего конденсатор от разряда. В спокойном состоянии транзистор закрыт, но, стоит подать на соответствующую строку матрицы электрический сигнал, как спустя мгновение-другое (конкретное время зависит от конструктивных особенностей и качества изготовления микросхемы) он откроется, соединяя обкладку конденсатора с соответствующим ей столбцом.
Чувствительный усилитель (sense amp), подключенный к каждому из столбцов матрицы, реагируя на слабый поток электронов, устремившихся через открытые транзисторы с обкладок конденсаторов, считывает всю страницу целиком. Это обстоятельство настолько важно, что последняя фраза вполне заслуживает быть выделенной курсивом. Именно страница является минимальной порцией обмена с ядром динамической памяти. Чтение/запись отдельно взятой ячейки невозможно! Действительно, открытие одной строки приводит к открытию всех, подключенных к ней транзисторов, а, следовательно, — разряду закрепленных за этими транзисторами конденсаторов.
Чтение ячейки деструктивно по своей природе, поскольку sense amp (чувствительный усилитель) разряжает конденсатор в процессе считывания его заряда. «Благодаря» этому динамическая память представляет собой память разового действия. Разумеется, такое положение дел никого устроить не может, и потому во избежание потери информации считанную строку приходится тут же перезаписывать вновь. В зависимости от конструктивных особенностей эту миссию выполняет либо программист, либо контроллер памяти, либо сама микросхема памяти. Практически все современные микросхемы принадлежат к последней категории. Редко какая из них поручает эту обязанность контроллеру, и уж совсем ни когда перезапись не возлагается на программиста.
Ввиду микроскопических размеров, а, следовательно, емкости конденсатора записанная на нем информация хранится крайне недолго, — буквально сотые, а то тысячные доли секунды. Причина тому — саморазряд конденсатора. Несмотря на использование высококачественных диэлектриков с огромным удельным сопротивлением, заряд стекает очень быстро, ведь количество электронов, накопленных конденсатором на обкладках, относительно невелико. Для борьбы с «забывчивостью» памяти прибегают к ее регенерации — периодическому считыванию ячеек с последующей перезаписью. В зависимости от конструктивных особенностей «регенератор» может находиться как в контроллере, так и в самой микросхеме памяти. Например, в компьютерах XT/AT регенерация оперативной памяти осуществлялась по таймерному прерыванию каждые 18 мс через специальный канал DMA (контроллера прямого доступа). И всякая попытка «замораживания» аппаратных прерываний на больший срок приводила к потере и/или искажению оперативных данных, что не очень-то радовало программистов, да к тому же снижало производительность системы, поскольку во время регенерации память была недоступна. Сегодня же регенератор чаще всего встраивается внутрь самой микросхемы, причем перед регенерацией содержимое обновляемой строки копируется в специальный буфер, что предотвращает блокировку доступа к информации.
Conventional DRAM (Page Mode DRAM) — «обычная» DRAM
Разобравшись с устройством и работой ядра памяти, перейдем к рассмотрению ее интерфейса. Физически микросхема памяти (не путать с модулями памяти) представляет собой прямоугольный кусок керамики (или пластика) «ощетинившийся» с двух (реже — с четырех) сторон множеством ножек. Что это за ножки?
В первую очередь выделим среди них линии адреса и линии данных. Линии адреса, как и следует из их названия, служат для выбора адреса ячейки памяти, а линии данных — для чтения и для записи ее содержимого. Необходимый режим работы определяется состоянием специального вывода Write Enable (Разрешение Записи).
Низкий уровень сигнала WE готовит микросхему к считыванию состояния линий данных и записи полученной информации в соответствующую ячейку, а высокий, наоборот, заставляет считать содержимое ячейки и «выплюнуть» его значения в линии данных.
Такой трюк значительно сокращает количество выводов микросхемы, что в свою очередь уменьшает ее габариты. А, чем меньше габариты, тем выше предельно допустимая тактовая частота. Почему? Увы! В двух словах не расскажешь — тут замешен целый ряд физических явлений и эффектов. Во-первых, в силу ограниченной скорости распространения электричества, длины проводников, подведенных к различным ножкам микросхемы, должны не сильно отличаться друг от друга, иначе сигнал от одного вывода будет опережать сигнал от другого. Во-вторых, длины проводников не должны быть очень велики — в противном случае задержка распространения сигнала «съест» все быстродействие. В-третьих, любой проводник действует как приемная и как передающая антенна, причем уровень помех резко усиливается с ростом тактовой частоты. Паразитному антенному эффекту можно противостоять множеством способов (например, путем перекашивания сигналов в соседних разрядах), но самой радикальной мерой было и до сих пор остается сокращение количества проводников и уменьшение их длины. Наконец, в-четвертых, всякий проводник обладает электрической емкостью. А емкость и скорость передачи данных — несовместимы! Вот только один пример: «:первый трансатлантический кабель для телеграфа был успешно проложен в 1858 году,: когда напряжение прикладывалось к одному концу кабеля, оно не появлялось немедленно на другом конце и вместо скачкообразного нарастания достигало стабильного значения после некоторого периода времени. Когда снимали напряжение, напряжение приемного конца не падало резко, а медленно снижалось. Кабель вел себя как губка, накапливая электричество. Это свойство мы теперь называем емкостью»
Таким образом, совмещение выводов микросхемы увеличивает скорость обмена с памятью, но не позволяет осуществлять чтение и запись одновременно. (Забегая вперед, отметим, что, размещенные внутри кристалла процессора микросхемы кэш-памяти, благодаря своим микроскопическим размерам на количество ножек не скупятся и беспрепятственно считывают ячейку во время записи другой).
Столбцы и строки матрицы памяти тем же самым способом совмещаются в единых адресных линиях. В случае квадратной матрицы количество адресных линий сокращается вдвое, но и выбор конкретной ячейки памяти отнимает вдвое больше тактов, ведь номера столбца и строки приходится передавать последовательно. Причем, возникает неоднозначность, что именно в данный момент находится на адресной линии: номер строки или номер столбца? А, быть может, и вовсе не находится ничего? Решение этой проблемы потребовало двух дополнительных выводов, сигнализирующих о наличии столбца или строки на адресных линиях и окрещенных RAS (от row address strobe — строб адреса строки) и CAS (от column address strobe — строб адреса столбца) соответственно. В спокойном состоянии на обоих выводах поддерживается высокий уровень сигнала, что говорит микросхеме: никакой информации на адресных линиях нет и никаких действий предпринимать не требуется.
Но вот программист захотел прочесть содержимое некоторой ячейки памяти. Контроллер преобразует физический адрес в пару чисел — номер строки и номер столбца, а затем посылает первый из них на адресные линии. Дождавшись, когда сигнал стабилизируется, контроллер сбрасывает сигнал RAS в низкий уровень, сообщая микросхеме памяти о наличии информации на линии. Микросхема считывает этот адрес и подает на соответствующую строку матрицы электрический сигнал. Все транзисторы, подключенные к этой строке, открываются и бурный поток электронов, срываясь с насиженных обкладок конденсатора, устремляется на входы чувствительного усилителя. Чувствительный усилитель декодирует всю строку, преобразуя ее в последовательность нулей и единиц, и сохраняет полученную информацию в специальном буфере. Все это (в зависимости от конструктивных особенностей и качества изготовления микросхемы) занимает от двадцати до сотни наносекунд, в течение которых контроллер памяти выдерживает терпеливую паузу. Наконец, когда микросхема завершает чтение строки и вновь готова к приему информации, контроллер подает на адресные линии номер колонки и, дав сигналу стабилизироваться, сбрасывает CAS в низкое состояние. «Ага!», говорит микросхема и преобразует номер колонки в смещение ячейки внутри буфера. Остается всего лишь прочесть ее содержимое и выдать его на линии данных. Это занимает еще какое-то время, в течение которого контроллер ждет запрошенную информацию. На финальной стадии цикла обмена контроллер считывает состояние линий данных, дезактивирует сигналы RAS и CAS, устанавливая их в высокое состояние, а микросхема берет определенный тайм-аут на перезарядку внутренних цепей и восстановительную перезапись строки.
Задержка между подачей номера строки и номера столбца на техническом жаргоне называется «RAS to CAS delay» (на сухом официальном языке — tRCD). Задержка между подачей номера столбца и получением содержимого ячейки на выходе — «CAS delay» (или tCAC), а задержка между чтением последней ячейки и подачей номера новой строки — «RAS precharge» (tRP). Здесь и далее будут использоваться исключительно жаргонизмы — они более наглядны и к тому же созвучны соответствующим настойкам BIOS, что упрощает восприятие материала неподготовленными читателями.
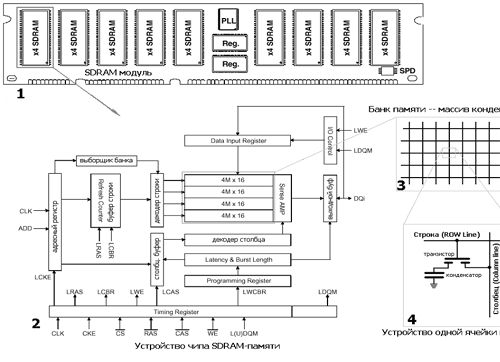
Рисунок 2 Схематическое изображение модуля оперативной памяти (1); микросхемы памяти (2); матрицы (3) и отдельной ячейки памяти (4). 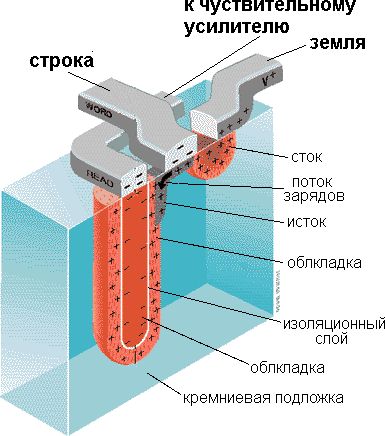
Рисунок 3 Устройство ячейки динамической памяти.
Эволюция динамической памяти.
В микросхемах памяти, выпускаемых вплоть до середины девяностых, все три задержки (RAS to CAS Delay, CAS Delay и RAS precharge) в сумме составляли порядка 200 нс., что соответствовало двум тактам в 10 мегагерцовой системе и, соответственно, двенадцати — в 60 мегагерцовой. С появлением Intel Pentium 60 (1993 год) и Intel 486DX4 100 (1994 год) возникла потребность в совершенствовании динамической памяти — прежнее быстродействие уже никого не устраивало.
FPM DRAM (Fast Page Mode DRAM) быстрая страничная память
Первой ласточкой стала FPM-DRAM — Fast-Page Mode DRAM (Память быстрого страничного режима), разработанная в 1995 году. Основным отличием от памяти предыдущего поколения стала поддержка сокращенных адресов. Если очередная запрашиваемая ячейка находится в той же самой строке, что и предыдущая, ее адрес однозначно определяется одним лишь номером столбца и передача номера строки уже не требуется. За счет чего это достигается? Обратимся к диаграмме, изображенной на рис.4. Смотрите, в то время как при работе с обычной DRAM (верхняя диаграмма) после считывания данных сигнал RAS дезактивируется, подготавливая микросхему к новому циклу обмена, контроллер FPM-DRAM удерживает RAS в низком состоянии, избавляясь от повторной пересылки номера строки.
При последовательном чтении ячеек памяти, (равно как и обработке компактных одно-двух килобайтовых структур данных), время доступа сокращается на 40%, а то и больше, ведь обрабатываемая строка находится во внутреннем буфере микросхемы, и обращаться к матрице памяти нет никакой необходимости!
Правда, хаотичное обращение к памяти, равно как и перекрестные запросы ячеек из различных страниц, со всей очевидностью не могут воспользоваться преимуществами передачи сокращенных адресов и работают с FPM-DRAM в режиме обычной DRAM. Если очередная запрашиваемая ячейка лежит вне текущей (так называемой, открытой) строки, контроллер вынужден дезактивировать RAS, выдержать паузу RAS precharge на перезарядку микросхемы, передать номер строки, выдержать паузу RAS to CAS delay и лишь затем он сможет приступить к передаче номера столбца.
Ситуация, когда запрашиваемая ячейка находится в открытой строке, называется «попаданием на страницу» (Page Hit), в противном случае говорят, что произошел промах (Page Miss). Поскольку, промах облагается штрафными задержками, критические к быстродействию модули должны разрабатываться с учетом особенностей архитектуры FPM-DRAM, так что абстрагироваться от ее устройства уже не получается.
Возникла и другая проблема: непостоянство времени доступа затрудняет измерение производительности микросхем памяти и сравнение их скоростных показателей друг с другом. В худшем случае обращение к ячейке составляет RAS to CAS Delay + CAS Delay + RAS precharge нс., а в лучшем: CAS Delay нс. Хаотичное, но не слишком интенсивное обращение к памяти (так, чтобы она успевала перезарядиться) требует не более RAS to CAS Delay + CAS Delay нс.
Поскольку, величины RAS to CAS Delay, CAS Delay и RAS precharge непосредственно не связаны друг с другом и в принципе могут принимать любые значения, достоверная оценка производительность микросхемы требует для своего выражения как минимум трех чисел. Однако производители микросхем в стремлении приукрасить реальные показатели, проводят только два: RAS to CAS Delay + CAS Delay и CAS Delay. Первое (называемое так же «временем [полного] доступа») характеризует время доступа к произвольной ячейке, а второе (называемое так же «временем рабочего цикла») — время доступа к последующим ячейкам уже открытой строки. Время, необходимое для регенерации микросхемы (т.е. RAS precharge) из полного времени доступа исключено. (Вообще-то, в технической документации, кстати, свободно доступной по Интернету, приводятся все значения и тайминги, так что никакого произвола в конечном счете нет).
Формула памяти
К середине девяностых среднее значение RAS to CAS Delay составляло порядка 30 нс., CAS Delay — 40 нс., а RAS precharge — менее 30 нс. (наносекунд). Таким образом, при частоте системной шины в 60 МГц (т.е. ~17 нс.) на открытие и доступ к первой ячейки страницы уходило около 6 тактов, а на доступ к остальным ячейкам открытой страницы — около 3 тактов. Схематически это записывается как 6-3-x-x и называется формулой памяти.
Формула памяти упрощает сравнение различных микросхем друг с другом, однако для сравнения необходимо знать преобладающий тип обращений к памяти: последовательный или хаотичный. Например, как узнать, что лучше: 5-4-x-x или 6-3-x-x? В данной постановке вопрос вообще лишен смысла. Лучше для чего? Для потоковых алгоритмов с последовательной обработкой данных, бесспорно, предпочтительнее последний тип памяти, в противном случае сравнение бессмысленно, т.к. чтение двух несмежных ячеек займет не 5-5-х-х и, соответственно, 6-6-х-х тактов, а 5+RAS precharge-5+RAS precharge-x-x и 6+RAS prechange-6+RAS prechange-x-x. Поскольку время регенерации обоих микросхем не обязательно должно совпадать, вполне может сложиться так, что микросхема 6-3-x-x окажется быстрее и для последовательного, и для хаотичного доступа. Поэтому, практическое значение имеет сравнение лишь вторых цифр — времени рабочего цикла. Совершенствуя ядро памяти, производители сократили его сначала до 35, а затем и до 30 нс., достигнув практически семикратного превосходства над микросхемами прошлого поколения.
EDO-DRAM (Extended Data Out) память с усовершенствованным выходом
Между тем тактовые частоты микропроцессоров не стояли на месте, а стремительно росли, вплотную приближаясь к рубежу в 200 МГц. Рынок требовал качественного нового решения, а не изнуряющей борьбы за каждую наносекунду. Инженеров вновь отправили к чертежным доскам, где (году эдак в 1996) их осенила очередная идея. Если оснастить микросхему специальным триггером-защелкой, удерживающим линии данных после исчезновения сигнала CAS, станет возможным дезактивировать CAS до окончания чтения данных, подготавливая в это время микросхему к приему номера следующего столбца.
Взгляните на диаграмму рис. 4: видите, у FPM низкое состояние CAS удерживается до окончания считывания данных, затем CAS дезактивируется, выдерживается небольшая пауза на перезарядку внутренних цепей, и только после этого на адресную шину подается номер колонки следующей ячейки. В новом типе памяти, получившем название EDO-DRAM (Extend Data Output), напротив, CAS дезактивируется в процессе чтения данных параллельно с перезарядкой внутренних цепей, благодаря чему номер следующего столбца может подаваться до завершения считывания линий данных. Продолжительность рабочего цикла EDO-DRAM (в зависимости от качества микросхемы) составляла 30, 25 и 20 нс., что соответствовало всего двум тактам в 66 МГц системе. Совершенствование производственных технологий сократило и полное время доступа. На частоте 66 МГц формула лучших EDO-микросхем выглядела так: 5-2-x-x. Простой расчет позволяет установить, что пиковый прирост производительности (в сравнении с FPM-DRAM) составляет около 30%, однако, во многих компьютерных журналах тех лет фигурировала совершенно немыслимая цифра 50%, — якобы настолько увеличивалась скорость компьютера при переходе с FPM на EDO. Это могло быть лишь при сравнении худшей FMP-DRAM с самой «крутой» EDO-памятью, т.е. фактически сравнивались не технологии, а старые и новые микросхемы.
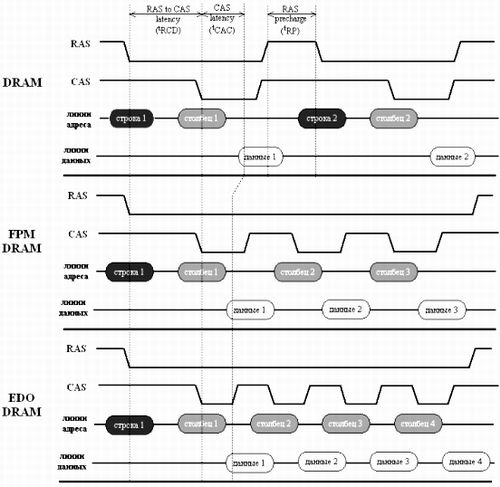
Рисунок 4 Временная диаграмма, иллюстрирующая работу некоторых типов памяти
BEDO (Burst EDO) — пакетная EDO RAM
Двукратное увеличение производительности было достигнуто лишь в BEDO-DRAM (Burst EDO). Добавив в микросхему генератор номера столбца, конструкторы ликвидировали задержку CAS Delay, сократив время цикла до 15 нс. После обращения к произвольной ячейке микросхема BEDO автоматически, без указаний со стороны контроллера, увеличивает номер столбца на единицу, не требуя его явной передачи. По причине ограниченной разрядности адресного счетчика (конструкторы отвели под него всего лишь два бита) максимальная длина пакета не могла превышать четырех ячеек (22=4).
Забегая вперед, отметим, что процессоры Intel 80486 и Pentium в силу пакетного режима обмена с памятью никогда не обрабатывают менее четырех смежных ячеек за раз. Поэтому, независимо от порядка обращения к данным, BEDO всегда работает на максимально возможной скорости и для частоты 66 Мгц ее формула выглядит так: 5-1-1-1, что на ~40% быстрее EDO-DRAM!
Все же, несмотря на свои скоростные показатели, BEDO оказалась не конкурентоспособной и не получила практически никакого распространения. Просчет состоял в том, что BEDO, как и все ее предшественники, оставалась асинхронной памятью. Это накладывало жесткие ограничения на максимально достижимую тактовую частоту, ограниченную 60 — 66 (75) мегагерцами. Действительно, пусть время рабочего цикла составляет 15 нс. (1 такт в 66 MHz системе). Однако, поскольку «часы» контроллера памяти и самой микросхемы памяти не синхронизованы, нет никаких гарантий, что начало рабочего цикла микросхемы памяти совпадет с началом такового импульса контроллера, вследствие чего минимальное время ожидания составляет два такта. Вернее, если быть совсем точным, рабочий цикл микросхемы памяти никогда не совпадает с началом тактового импульса. Несколько наносекунд уходит на формирование контроллером управляющего сигнала RAS или CAS, за счет чего он уже не совпадет с началом тактирующего импульса. Еще несколько наносекунд требуется для стабилизации сигнала и «осмысления» его микросхемой, причем, сколько именно времени потребуется заранее определить невозможно, т.к. на результат влияет и температура, и длина проводников, и помехи на линии, и: еще миллион факторов!
SDRAM (Synchronous DRAM) — синхронная DRAM
Появление микропроцессоров с шинами на 100 MHz привело к радикальному пересмотру механизма управления памятью, и подтолкнуло конструкторов к созданию синхронной динамической памяти — SDRAM (Synchronous-DRAM). Как и следует из ее названия, микросхемы SDRAM памяти работают синхронно с контроллером, что гарантирует завершение цикла в строго заданный срок. (Помните, «как хочешь, крутись, теща, но что бы к трем часам как штык была готова»). Кроме того, номера строк и столбцов подаются одновременно, с таким расчетом, чтобы к приходу следующего тактового импульса сигналы уже успели стабилизироваться и были готовы к считыванию.
Так же, в SDRAM реализован усовершенствованный пакетный режим обмена. Контроллер может запросить как одну, так и несколько последовательных ячеек памяти, а при желании — всю строку целиком! Это стало возможным благодаря использованию полноразрядного адресного счетчика уже не ограниченного, как в BEDO, двумя битами.
Другое усовершенствование. Количество матриц (банков) памяти в SDRAM увеличено с одного до двух (а, в некоторых моделях, и четырех). Это позволяет обращаться к ячейкам одного банка параллельно с перезарядкой внутренних цепей другого, что вдвое увеличивает предельно допустимую тактовую частоту. Помимо этого появилась возможность одновременного открытия двух (четырех) страниц памяти, причем открытие одной страницы (т.е. передача номера строки) может происходить во время считывания информации с другой, что позволяет обращаться по новому адресу столбца ячейки памяти на каждом тактовом цикле.
В отличие от FPM-DRAM\EDO-DRAM\BEDO, выполняющих перезарядку внутренних цепей при закрытии страницы (т.е. при дезактивации сигнала RAS), синхронная память проделывает эту операцию автоматически, позволяя держать страницы открытыми столь долго, сколько это угодно.
Наконец, разрядность линий данных увеличилась с 32 до 64 бит, что еще вдвое увеличило ее производительность!
Формула чтения произвольной ячейки из закрытой строки для SDRAM обычно выглядит так: 5-1-x-x, а открытой так: 3-1-х-х.
В настоящее время (2002 год) подавляющее большинство персональных компьютеров оснащаются SDRAM памятью, которая прочно удерживает свои позиции, несмотря на активный натиск современных разработок.
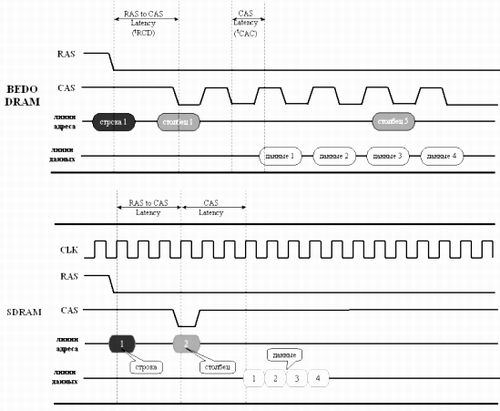
Рисунок 5 Временная диаграмма, иллюстрирующая работу современных типов памяти
DDR SDRAM, SDRAM II (Double Data Rate SDRAM)
SDRAM с удвоенной скоростью передачи данных
Дальнее развитие синхронной памяти привело к появлению DDR-SDRAM — Double Data Rate SDRAM (SDRAM удвоенной скорости передачи данных). Удвоение скорости достигается за счет передачи данных и по фронту, и по спаду тактового импульса (в SDRAM передача данных осуществляется только по фронту). Благодаря этому эффективная частота увеличивается в два раза — 100 MHz DDR-SDRAM по своей производительности эквивалента 200 MHz SDRAM. Правда, по маркетинговым соображениям, производители DDR-микросхем стали маркировать их не тактовой /* рабочей */ частой, а максимально достижимой пропускной способностью, измеряемой в мегабайтах в секунду. Т.е. DDR-1600 работает вовсе не 1.6 GHz (что пока является недостижимым идеалом), а всего лишь на 100 MHz. Соответственно, DDR 2100 работает на частоте 133 MHz.
Претерпела изменения и конструкция управления матрицами (банками) памяти. Во-первых, количество банков увеличилось с двух до четырех, а, во-вторых, каждый банк обзавелся персональным контроллером (не путать с контроллером памяти!), в результате чего вместо одной микросхемы мы получили как бы четыре, работающих независимо друг от друга. Соответственно, максимальное количество ячеек, обрабатываемых за один такт, возросло с одной до четырех.
RDRAM (Rambus DRAM) — Rambus-память
С DDR-SDRAM жесточайше конкурирует Direct RDRAM, разработанная компанией Rambus. Вопреки распространенному мнению, ее архитектура довольно прозаична и не блещет новизной. Основных отличий от памяти предыдущих поколений всего три:
- а) увеличение тактовой частоты за счет сокращения разрядности шины,
- б) одновременная передача номеров строки и столба ячейки,
- в) увеличение количества банков для усиления параллелизма.
А теперь обо всем этом подробнее. Повышение тактовой частоты вызывает резкое усиление всевозможных помех и в первую очередь электромагнитной интерференции, интенсивность которой в общем случае пропорциональна квадрату частоты, а на частотах свыше 350 мегагерц вообще приближается к кубической. Это обстоятельство налагает чрезвычайно жесткие ограничения на топологию и качество изготовления печатных плат модулей микросхемы, что значительно усложняет технологию производства и себестоимость памяти. С другой стороны, уровень помех можно значительно понизить, если сократить количество проводников, т.е. уменьшить разрядность микросхемы. Именно по такому пути компания Rambus и пошла, компенсировав увеличение частоты до 400 MHz (с учетом технологии DDR эффективная частота составляет 800 MHz) уменьшением разрядности шины данных до 16 бит (плюс два бита на ECC). Таким образом, Direct RDRAM в четыре раза обгоняет DDR-1600 по частоте, но во столько же раз отстает от нее в разрядности! А от DDR 2100, Direct RDRAM даже отстает, притом, что себестоимость DDR заметно дешевле!
Второе (по списку) преимущество RDRAM — одновременная передача номеров строки и столбца ячейки — при ближайшем рассмотрении оказывается вовсе не преимуществом, а фичей — т.е. конструктивной особенностью. Это не уменьшает латентности доступа к произвольной ячейке (т.е. интервалом времени между подачей адреса и получения данных), т.к. она, латентность, в большей степени определяется скоростью ядра, а RDRAM функционирует на старом ядре. Из спецификации RDRAM следует, что время доступа составляет 38,75 нс. (для сравнения время доступа 100 MHz SDRAM составляет 40 нс.). Ну, и стоило бы огород городить?
Стоило! Большое количество банков позволяет (теоретически) достичь идеальной конвейеризации запросов к памяти, — несмотря на то, что данные поступают на шину лишь спустя 40 нс. после подачи запроса (что соответствует 320 тактам в 800 MHz системе), сам поток данных непрерывен.
Стоило?! Для потоковых алгоритмов последовательной обработки памяти это, допустим, хорошо, но во всех остальных случаях RDRAM не покажет никаких преимуществ перед DDR-SDRAM, а то и обычной SDRAM, работающей на скромной частоте в 100 MHz. К тому же (как будет показано ниже), «солидный» объем кэш-памяти современных процессоров позволяет обрабатывать подавляющее большинство запросов локально, вообще не обращаясь к основной памяти или на худой конец, отложить это обращение до «лучших времен». Производительность памяти реально ощущается лишь при обработке гигантских объемов данных, например редактировании изображений полиграфического качества в PhotoShop.
Таким образом, использование RDRAM в домашних и офисных компьютеров, ничем, кроме желания показать свою «крутость», не оправдано. Для высокопроизводительных рабочих станций лучший выбор — DDR-SDRAM, не уступающей RDRAM в производительности, но значительно выигрывающей у последней в себестоимости.
В этом свете становится не очень понятно стремление компании Intel к продвижению Rambus’а на рынке. Еще раз обращу внимание читателя: ничего революционного Rambus в себе не несет. Чрезвычайно сложная и требовательна к качеству производства интерфейсная обвязка, обеспечивает высокую тактовую частоту, но не производительность! Соотношение 400×2 MHz на 16 бит оптимальным соотношением категорически не является, уже хотя бы потому, что DDR-SDRAM без особых ухищрений тянет 133×2 MHz на 64 бит. Причем ее производители в ближайшем будущем планируют взять барьер в 200×4 MHz на 128 бит, что увеличит пропускную способность до 12,8 Гбайт/с., что в восемь раз превосходит пропускную способность Direct RDRAM при меньшей себестоимости и аппаратной сложности.
Не стоит, однако, бросаться и в другую крайность — считать Rambus «кривой», «идиотской» памятью. Отнюдь! Инженерный опыт, приобретенный в процессе создания этой, не побоюсь сказать, чрезвычайно высокотехнологичной памяти, несомненно, найдет себе применение в дальнейших разработках. Взять хотя бы машину Бэббиджа. Согласитесь, несмотря на передовые идеи, ее реальное воплощение проигрывало по всем позициям даже конторским счетам. Аналогично и с Direct RDRAM. Достичь пропускной способности в 1,6 Гбайт/с. можно и более прозаическими путями.

Рисунок 6 Внешний вид модуля Rambus-памяти 
Рисунок 7 Четыре Rambus-модуля, установленные на системную плату
Сравнительная характеристика основных типов памяти
С точки зрения пользователя PC главная характеристика памяти — это скорость или, выражаясь другими словами, ее быстродействие. Казалось, что может быть проще, чем измерять быстродействие? Достаточно подсчитать количество информации, выдаваемой памятью в единицу времени (скажем, Мегабайт в секунду), и. ничего не получится! Ведь, как мы уже знаем, время доступа к памяти непостоянно и в зависимости от ряда обстоятельств варьируется в очень широких пределах. Наибольшая скорость достигается при последовательном чтении, а наименьшая — при чтении в разброс.
Хорошо, условимся измерять максимально достижимое быстродействие памяти по скорости последовательного считывания ячеек. Конечно, это будет несколько идеализированная характеристика, ощутимо завышающая реальную производительность (ведь не все алгоритмы могут быть «заточены» под последовательный доступ), но. тут не обходится без тонкостей.
Современные модули памяти имеют несколько независимых банков и потому могут обрабатывать более одного запроса одновременно. Таким образом, несмотря на то, что выполнение каждого отдельно взятого запроса по-прежнему будут занимать весьма внушительное время (конденсаторное ядро так ведь и не было переработано!), запросы могут следовать непрерывно. А раз так, — непрерывно будут приходить и ответы.
Теоретически все так и есть, но на практике возникает множество затруднений. Основной камень преткновения — фундаментальная проблема зависимости по данным. Рассмотрим следующую ситуацию. Пусть ячейка N 1 хранит указатель на ячейку N 2, содержащую обрабатываемые данные. До того, как мы получим содержимое ячейки N 1, мы не сможем послать запрос на чтение ячейки N 2, поскольку, еще не знаем ее адрес. Следовательно, производительность памяти в данном конкретном случае будет определяться не пропускной способностью, а ее латентностью, т.е. полным временем доступа к одной ячейке.
Причем, описываемый случай отнюдь не является надуманным, скорее наоборот. Это — типичная ситуация. Базовые структуры данных — деревья и списки — имеют ярко выраженную зависимость по данным, т.к. объединяют свои элементы именно посредством указателей, что сводит на нет весь выигрыш от параллелизма. Большинство функции штатных библиотек Си/Си++ также имеют зависимость по данным и не могут обрабатывать их параллельно.
Маскировать латентность позволяют лишь очень немногие алгоритмы, да и то не без помощи специальных команд предвыборки (см. статью » Управление кэшированием в x86 процессорах старших поколений», опубликованную в апрельском номере журнала за этот год). Команды предвыборки, во-первых, отсутствуют в микропроцессорах Pentium младшего поколения. Во-вторых, они чрезвычайно аппаратно зависимы и требуют реализовать код как минимум в двух вариантах — отдельно для процессоров Pentium и отдельно для процессоров K6/K7, причем, реализация для Pentium-III будет весьма не оптимальна для Pentium-4 и, соответственно, наоборот. (На Pentium-II это же и вовсе не будет работать и вызовет исключение «неверный опкод»). Наконец, в-третьих, команды предвыборки до сих пор не поддерживаются ни одним оптимизатором, и вряд ли будут поддерживаться в ближайшем будущем. Ручная же оптимизация — слишком сложна и трудоемка, чтобы стать массовой.
Короче говоря, теоретическая пропускная способность памяти, заявленная производителями, совсем не то же самое, что и реальная производительность. Давайте, отбросив параллелизм (который все равно не ускоряет работу подавляющего большинства существующих на данный момент приложений) попробуем подсчитать максимально достижимую пропускную способность при обработке зависимых данных. Используем для этого следующую формулу:
здесь: C — пропускная способность (Мегабайт/c), N — разрядности памяти (бит), T — полное время доступа (нс.).
Сравнив полученные результаты с теоретической пропускной способностью (см. рис. 8), мы увидим, что, во-первых, расхождение между ними чрезвычайно велико и к тому же неуклонно увеличивается по мере совершенствования памяти. Во-вторых, при обработке зависимых данных эффективная производительность SDRAM и DDR-SDRAM практически неразличима, а Direct RDRAM и вовсе идет на уровне памяти начала девяностых. Причем, фактическая производительность всех типов памяти будет еще ниже, чем рассчитанная по формуле (1). Это объясняется тем, что, во-первых, современные процессоры обмениваются с памятью не отдельными ячейками, а блоками по 32 и ли 128 байт (в зависимости от длины кэш-линеек), вследствие чего издержки на хаотичный доступ чрезвычайно велики. Во-вторых, приведенная выше формула не учитывает ни латентности контроллера памяти, ни штрафа за асинхронность, ни времени регенерации памяти, ни.
Фактически, разница в реальной и заявленной производительности отличается приблизительно в десять раз для DDR-SDRAM и в пятьдесят (!) для Direct-Rambus. Кошмар! Что это: преднамеренное введение потребителя в заблуждение или несбалансированная конфигурация системы? Оказывается, верно последнее предположение.
Разработчики аппаратного обеспечения перегнали прогресс, заставив телегу бежать впереди лошади. Программистский мир к такому развитию событий оказался не готов и новые, замечательные возможности параллельной обработки памяти до сих пор остаются не востребованными и вряд ли будут востребованы в обозримом будущем.
Как минимум потребуется разработать принципиально новые алгоритмы обработки данных, обеспечить соответствующую поддержку параллелизма со стороны компилятора и/или штатных библиотек, наконец, маркетоидам надлежит придумать: зачем рядовому пользователю обрабатывать терабайты данных. Вообще-то, все три этих пункта давным-давно реализованы, но. только не на IBM PC, а на суперкомпьютерах! Однако, главное отличие суперкомпьютеров от персоналок заключается отнюдь не в вычислительной мощности, а в возложенных на них задачах. Задачи, стоящие перед персоналками, колоссальной пропускной способности просто не требуют (при грамотном подходе к программированию, конечно). И даже из тех, что требуют, далеко не все поддаются эффективному распараллеливанию по данным.
Короче говоря, «официальная» пропускная способность — это абстракция чистейшей воды, интересная скорее с маркетинговой точки зрения, но абсолютно бесполезная для конечного пользователя.
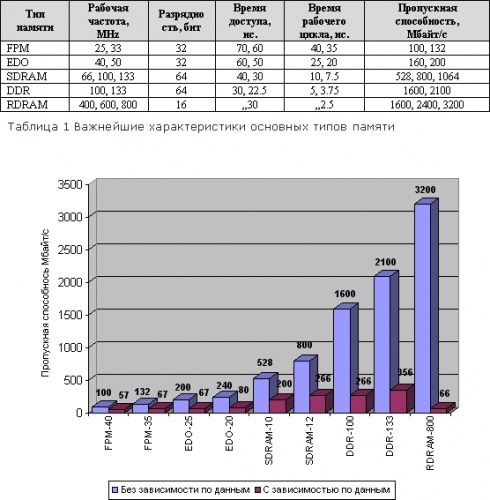
Рисунок 8 Максимально достижимая пропускная способность основных типов памяти при наличии зависимости по данным и при отсутствии таковой.
Взаимодействие памяти и процессора.
Ввиду несоответствия интерфейсов памяти и процессора, для совместного взаимодействия им необходим посредник — контроллер памяти. Контроллер памяти в значительной мере определяет скорость обмена с памятью а, значит, и быстродействие всей системы в целом.
В настоящее время, такие контролеры выпускаются не в виде отдельных микросхем, а входят в состав чипсета (см. рис. 9), поэтому, очень важно выбрать «правильный» чипсет. Чем они отличаются друг от друга, или на какие характеристики следует обращать внимание в первую очередь?
Прежде всего — синхронный или асинхронный режим работы. Синхронные чипсеты требуют, чтобы частота памяти совпадала с частой шины. Имея такой чипсет, вы не сможете использовать преимущества процессора с 133 MHz шиной, если у вас установлена память SDRAM PC 100. Асинхронные чипсета выгодно отличаются тем, что позволяют тактировать память «своей» частотой, не обязательно совпадающей с тактовой частотой системной шины. Благодаря этому, они поддерживают практически любые комбинации процессоров и памяти. Согласитесь, — немаловажно для апгрейда. Однако если тактовые частоты системной шины и памяти не могут быть соотнесены как целые числа, возникают штрафные задержки (см. рис. 10), негативно сказывающиеся на производительности.
Другой немаловажный момент — политика открытия страниц и максимально возможное количество одновременно открываемых страниц. Как уже было показано выше, удерживание сигнала RAS позволяет читать ячейки в пределах этой страницы передачей одного лишь адреса столбца, что значительно увеличивает производительность системы. Чем больше страниц удерживается в открытом состоянии, тем выше вероятность того, что очередной запрос попадет в уже открытую страницу и потому обработается значительно быстрее.
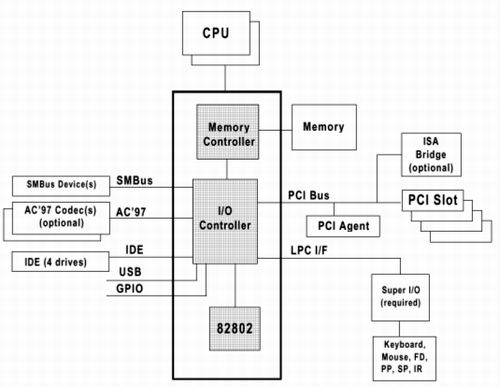
Рисунок 9 Контроллер памяти в современных системах интегрирован в чипсет 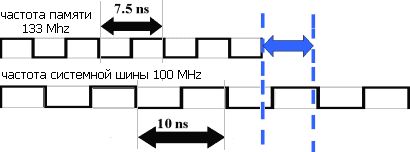
Рисунок 10 Если тактовая частота памяти и тактовая частота системной шины не могут быть соотнесены как целые числа возникают штрафные задержки на их синхронизацию.
Вычисление полного времени доступа.
Приводя формулу (1) мы упомянули, что она дает несколько завышенное представление о производительности памяти, т.к. не учитывает ряда факторов. Настало время восполнить этот пробел, рассмотрев процесс обращения к памяти под «микроскопом».
Рассмотрим следующий пример. Пусть у нас имеется 10-нс память и процессор CELERON-300A, с системной шиной на 66 MHz. Сколько тактов потребуется для чтения одной ячейки памяти? Чтобы вычислить это, разберем весь процесс обмена по «косточкам». Итак.
- процессор (вернее кэш-контроллер второго уровня) запрашивает 32 байта памяти и передает запрос чипсету. На это уходит один такт системной шины;
- в течение следующего такта чипсет вычисляет номер столбца и строки первой ячейки цепочки и смотрит: открыта ли соответствующая строка или нет?
- если строка действительно открыта, то чипсет выставляет сигнал CAS и спустя 2-3 такта (в зависимости от величины задержки CAS, обусловленной качеством микросхемы памяти) на шине появляются долгожданные данные;
- чипсет их считывает за один такт;
- еще 1 такт расходуется на передачу данных процессору;
- если адрес запрошенной ячейки кратен 32, она возвращается в первой интеграции цикла чтения, в противном случае нам придется немного подождать;
- три последующих ячейки считываются процессором за три такта — по такту на каждую;
Итак, по меньшей мере, требуется шесть тактов системной шины на чтение одной ячейки, а в худшем случае — все четырнадцать. Поскольку, в данном случае частота ядра процессора в 4.5 раза превышает частоту системной шины, чтение ячейки занимает от тридцати (6 x 5 = 30) до семидесяти (12 x 5 = 70) тактов процессора!
А теперь (интереса ради) попробуйте подсчитать: сколько тактов занимает одно обращение к памяти в системе вашей конфигурации.
Заключение
Сегодня, когда счет оперативной памяти пошел на сотни мегабайт, мы, программисты, наконец-то лишились «удовольствия» оптимизации своих программ по скорости и размеру одновременно. Пусть будет нужен хоть гигабайт — система выделит его за счет жесткого диска.
Правда, производительность подсистемы памяти все еще оставляет желать лучшего. Причем, современная ситуация даже хуже, чем десять-пятнадцать лет тому назад. Если персональные компьютеры конца восьмидесятых — начала девяностых оснащались микропроцессорами с тактовой частотой порядка 10 MHz и оперативной памятью со временем доступа 200 нс., типичная конфигурация ПК ближайшего будущего: 1.000 — 2.000 MHz и 20 ns. Нетрудно подсчитать, что во времена главенства IBM XT/AT обращение к одной ячейке занимало буквально пару тактов процессора и это притом, что большинство арифметических команд отнимало десятки тактов! Современные же процессоры тратят на чтение произвольной ячейки порой сотни тактов, выполняя в это же самое время чуть ли не по трое вычислительных инструкций за такт.
Несмотря на стремительный рост производительности оперативной памяти, наблюдающиеся в последние годы, разрыв «CPU vs Memory» растет с чудовищной быстротой. Забавно, но та же самая картина наблюдалась и тридцать-сорок лет назад, — в эпоху «больших» машин с быстродействующими (по тем временам!) процессорами и жутко медленной барабанной (а позже и ферритовой) памятью.
Как же конструкторы ЭВМ выходили из этой ситуации? Откроем, например, «Структуры ЭВМ и их математическое обеспечение» Л. Н. Королева: «Для того чтобы достичь необходимого баланса между высокой скоростью выполнения арифметических и логических действий в центральном процессоре и ограниченным быстродействием блоков оперативного ферритового запоминающего устройства (время цикла работы каждого блока — 2 мксек), были предприняты следующие меры.
Оперативное запоминающее устройство состоит из восьми блоков, допускающих одновременную выборку информации (командных слов и операндов), что резко повышает эффективное быстродействие системы памяти. Подряд идущие физические адреса памяти относятся к разным блокам, и если оказалось, например, так, что последовательно выбираемые операнды имеют последовательно возрастающие (убывающие) адреса, то они могут выбираться со средней скоростью, равной 2 мксек/8=0,25 мксек.
Второй структурной особенностью организации обращений к оперативному запоминающему устройству является метод буферизации, или метод накопления очереди заказов к системе памяти. В машине БЭСМ-6 существуют группы регистров, на которых хранятся запросы (адреса), называемые буферами адресов слов и команд. Разумеется, что эти буфера могут работать эффективно только в том случае, если структура машины позволяет просматривать команды «вперед», т. е. загодя готовить запросы. Устройство управления БЭСМ-6 позволяет это делать. Буфера адресов позволяют в конечном итоге сгладить неравномерность поступления запросов к памяти и тем самым повысить эффективность ее использования.
Третьей структурной особенностью БЭСМ-6 является метод использования сверхоперативной, не адресуемой из программы памяти небольшого объема, цель которого — автоматическая экономия обращений к основному оперативному запоминающему устройству. Эта сверхоперативная память управляется таким образом, что часто используемые операнды и небольшие внутренние командные циклы оказываются на быстрых регистрах и готовы к немедленному использованию в арифметическом устройстве или в системе управления машиной. Быстрые регистры в ряде случаев позволяют экономить до 60% всех обращений к памяти и уменьшают тем самым временные затраты на ожидание чисел и команд из основной памяти.
Следует еще раз подчеркнуть, что об использовании быстрых регистров заботится аппаратура самой машины и при составлении программ об экономии обращений к памяти думать нет необходимости.
Эти структурные особенности БЭСМ-6 получили название водопроводного принципа построения структуры машины. В самом деле, если подсчитать время от начала выполнения команды до его окончания, то для каждой команды оно будет очень велико, однако глубокий параллелизм выполнения, просмотр вперед, наличие буфера адресов, быстрых регистров приводят к тому, что «поток» команд и темп обработки информации очень высок. Аналогия с водопроводом состоит в том, что если проследить время, за которое частица воды проходит по некоторому участку водопровода, то оно будет большим, хотя скорость на выходе потока может быть очень велика. Четвертой структурной особенностью БЭСМ-6, имеющей очень важное значение для построения операционных систем и работы машины в мультипрограммном режиме, является принятый аппаратный способ преобразования математических, или виртуальных адресов в физические адреса машины. В машине БЭСМ-6 четко выдержано деление на физическую и математическую память, принята постраничная организация, однако способ отображения, заложенный в аппаратуру, значительно отличается от того, который был применен в машине «.
Такое впечатление, что читаешь описание процессора Pentium, — настолько эти решения похожи! Создается впечатление, что никакого прогресса вообще нет. Меняются лишь технологии и проектные нормы, но эксплуатируется один и те же идеи. Хороший повод для размышлений, не правда ли, господа?
Эволюция памяти – от каменной до электронной
Тема хранения информации была актуальна во все времена — начиная с рассвета человеческой цивилизации и по сей день. Свой авторский взгляд на историю средств хранения предлагает Джереми Кук, публикующий свои статьи на сайте EETimes.
В продолжение темы об эволюции цифровой памяти я подготовил что-то вроде слайд-шоу, иллюстрирующего этот прогресс. Полный обзор истории памяти – занятие слишком утомительное, поэтому я выбрал список того, что считаю в ней основным. Приглашаю всех высказывать свое мнение о подборке в комментариях.
Письменность

Источник: Университет Чикаго
Еще не электронная и даже не механическая, письменность сама по себе была невероятным открытием. Она позволила не только общаться людям, находящимся в разных местах, но и передавать знания из поколения в поколение. Согласно исследованиям университета Чикаго, письменность появилась около 3500 до н.э. и это событие стало «началом информационной революции». По-моему, лучше и не скажешь.Перфокарты

Иллюстрация в журнале Scientific American от 30 августа 1890 г. Источник: Wikipedia
Перфокарты громко заявили о себе при переписи населения США 1890 года; машина, изобретенная Германом Холлеритом, обработала ее результаты в течение года – людям понадобилось бы на это в 10 раз больше времени. Идею для устройства подсказали кондукторы в поездах, компостировавшие билеты пассажиров; большое влияние оказали также машины французского ткача Жозефа-Мари Жаккарда, использовавшие перфоленту для управления ткацким процессом.Триггер
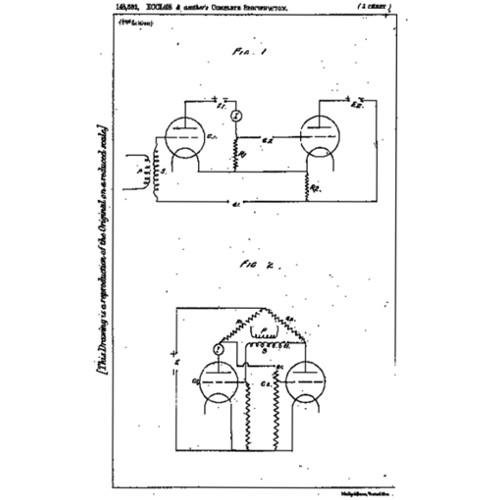
Схема триггера из патента Екклеса и Джордана, 1918 г. Источник: Wikipedia
Триггер, изобретенный в 1918 году, дает нам подсказку, как работает современная компьютерная память. Эти старомодные громоздкие устройства, способные сохранять и изменять свое состояние, зависящее от внешнего электрического сигнала, принципиально не так далеки от того, как компьютеры работают сейчас.DRAM

MT4C1024 — интегрированный DRAM модуль производства Micron Technology. Источник: Wikipedia
DRAM (Dynamic random access memory, Динамическая память с произвольным доступом), изобретенная в 1966 году (не путать с древней монетой!), использовала конденсаторы для хранения информации. Заряженный конденсатор представлял собой единицу, разряженный – ноль. Упоминавшийся в названии термин «динамический» означал не функциональную особенность, а свойство конденсаторов со временем терять свой заряд, что вызывало необходимость в перезарядке.SDRAM

Source: Royan/Wikipedia commons
SDRAM (Synchronous Dynamic Random Access Memory, Синхронная динамическая память с произвольным доступом) имела ограниченное применение еще в 70-х, однако заявила о себе широко только в 1993. Ранее RAM изменяла свое состояние так быстро, как было возможно, чтобы принять данные, синхронная же DRAM использовала тактовый генератор компьютера для настройки процесса хранения. Это позволило разделить данные на отдельные банки для синхронного исполнения нескольких операций с памятью одновременно.EPROM

Первый EPROM Intel, 1971 г. Источник: Wikipedia
Дов Фроман разработал стираемую программируемую память только для чтения (EPROM, Erasable Programmable Read Only Memory) в 1971 году в Intel. Она энергонезависима, то есть содержимое памяти не уничтожается при потере питания. Эти чипы программируются с помощью электрического тока, информация стирается путем облучения ультрафиолетовым светом.Дисковод

Источник: Michael Holley/Wikipedia
Побывавший в 1975 году на обложке журнала Popular Electronics, Altair 8800 стал первым компьютером для тысяч новоявленных компьютерных гиков. Хотя об этом компьютере можно рассказать много любопытного, в данной статье нас более всего интересует его 8-дюймовый дисковод, изображенный на фото. Согласно rwebs.net, диск мог хранить 300,000 байт. Сейчас нам странно видеть размер памяти без добавления приставки мега- или гига-, однако в то время это был приличный объем. Любопытно, что вы могли также приобрести и кассетный интерфейс, если дисковод не пришелся вам по душе.EEPROM

Источник: Amit Bhawani
Электрически стираемая программируемая память только для чтения (EPROM, Electrically Erasable Programmable Read Only Memory) появилась в 1978 году. Ее преимуществом по сравнению с EPROM стала возможность программирования и стирания данных во время использования. Имелось и одно существенное ограничение – в количестве циклов перепрограммирования. Однако в современных чипах количество циклов чтения-записи было значительно увеличено.Жесткий диск

Источник: Ian Wilson/Wikipedia
Seagate произвел свой первый 5-дюймовый жесткий диск в 1980 году. С этого времени компоненты памяти начинают напоминать те, которые мы имеем сейчас, однако есть и нюансы. Скажем, в том же году IBM выпустила первый винчестер емкостью 1 Гб – он весил 550 кг.Аудио CD

Брошюра к проигрывателю Sony CDP-101. Источник: TechHive.com
Продажи аудио CD начались в 1982. Первоначально они не предназначались для компьютеров, однако представляли собой средство хранения цифровой информации, и к 1985 году появились первые приводы CD-ROM. CD опережали свое время – лишь в начале 90-х компьютеры догнали их по объемам хранимой мультимедийной информации.
Несмотря на возраст, CD до сих пор, пусть и не так широко, используются для распространения данных. 30 лет – это огромный срок для всего цифрового.Флеш память

Чип слева — флеш память, справа — контроллер. Источник: Wikimedia Commons
Флеш память была изобретена в 80-х и представлена публике в 1988. Технически представляя собой разновидность EEPROM, флеш память существенно превосходит предшественников по скорости. Были разработаны две разновидности, основанные на логических вентилях NAND и NOR соответственно. Технология эксплуатируется по сегодняшний день, одним из наиболее ее распространенных примеров являются карты памяти Compact Flash.DDR SDRAM

Память Corsair DDR-400 с радиаторами. Источник: Martyn M aka Martyx/Wikipedia
Торговая ассоциация JDEC сертифицировала DDR SDRAM (Double Data Rate Synchronous Dynamic Random Access Memory, Синхронная динамическая память с произвольным доступом и удвоенной скоростью передачи данных) в 2000 году. Как следует из названия, при определенных условиях этот тип памяти может обеспечить двойную скорость данных по сравнению с обычной SDRAM.
Вслед за DDR SDRAM последовала DDR2, представленная в 2003 и обеспечивавшая еще примерно двукратный прирост. Затем DDR3 удвоила его еще раз в 2007. Если кого-то не удовлетворяет 8-кратное увеличение, DDR4 уже не за горами; помимо удвоения скорости, она имеет более низкое рабочее напряжение.UFS

Источник: Toshiba
JDEC опубликовала стандарт UFS (Universal Flash Storage, Универсальный флеш-накопитель) в 2012 году и обновила его в сентябре 2013. В дополнение в функциям энергосбережения, эти чипы обеспечат дуплексную пропускную способность данных 300 Мбит/с. Будет интересно посмотреть, как этот тип памяти будет развиваться в будущем.Трехмерная память

Источник: Micron/TechWeekEurope.co.uk
Помимо DDR4 и UFS, еще один памяти у нас на горизонте – трехмерная память. Исчерпав возможности плоских чипов, мы пытаемся выжать максимум из третьего измерения. Эта перспективная технология описана в посте Janine Love.1 ТБ USB-носитель

Источник: HardwareZone
Как я уже отмечал ранее, Kingston в 2013 году выпустил терабайтный USB-носитель. До сих пор поражаюсь плотности данных в этом устройстве размером в несколько сантиметров.
Удивительно, как далеко зашел прогресс в области памяти. Неужели и в дальнейшем мы будем наблюдать столь гигантские прорывы?Оригинальная версия поста опубликована на сайте EETimes.
ОЗУ (оперативное запоминающее устройство)

Оперативная память ОЗУ (оперативное запоминающее устройство) является одним из основных компонентов компьютера и служит для временного хранения данных и программ во время их выполнения. Ее основная задача — обеспечить быстрый доступ к данным, которые используются процессором компьютера.
ОЗУ является переходным типом памяти, то есть данные в ней хранятся только во время работы компьютера и не сохраняются после его выключения. Когда компьютер включен, операционная система и другие программы загружаются в оперативную память, чтобы процессор мог с ними работать. Чем больше оперативной памяти у компьютера, тем больше данных и программ он может одновременно обрабатывать без замедления работы.
В общем случае термин «оперативная память» относится исключительно к твердотельным запоминающим устройствам (DRAM или SRAM), а точнее к основной памяти в большинстве компьютеров. ОЗУ также играет важную роль при запуске компьютера и загрузке операционной системы. При включении компьютера, операционная система загружается с жесткого диска в оперативную память, где она может быстро выполняться процессором.
Кроме того, оперативная память используется для кэширования данных, призванного ускорить доступ к наиболее часто используемым данным и программам.
Кэш — это небольшая область оперативной памяти, ближе расположенная к процессору, чем основная память компьютера. Когда данные или программы необходимы процессору, он сначала проверяет кэш, и если данные там уже есть, то доступ к ним происходит значительно быстрее, чем если бы они находились только в основной памяти.Теперь хотел поговорить о видах оперативной памяти, какие бывают и как используются:
• DRAM (Dynamic Random Access Memory) — это самый распространенный тип оперативной памяти. Память построена на основе конденсаторов и транзисторов и требует перезаписи данных каждый раз, когда они обновляются. DRAM является более медленным и дешевым в сравнении с другими типами ОЗУ. Первой коммерческой микросхемой динамической памяти стала INTEL 1103 объёмом 1 кБит, выпущенная в продажу в октябре 1970 года.
• SRAM (Static Random Access Memory) — Статическая память с произвольным доступом — полупроводниковая оперативная память. Более быстрый и дорогой тип оперативной памяти. Он использует бистабильные флип-флопы для хранения данных и не требует перезаписи каждый раз, как DRAM. SRAM используется в некоторых специализированных устройствах и кэш-памяти процессора, так как обеспечивает более быстрый доступ к данным.
• SDRAM (Synchronous Dynamic Random Access Memory) — эволюция DRAM, которая работает синхронно с шиной системной платы. SDRAM значительно более быстрая по сравнению с обычной DRAM и широко используется в современных компьютерах и ноутбуках.
• DDR SDRAM (Double Data Rate Synchronous Dynamic Random Access Memory) — это дальнейшее развитие SDRAM. DDR SDRAM удваивает частоту работы памяти, что позволяет ей передавать данные вдвое быстрее. В настоящее время самая широко распространенная форма оперативной памяти. • DDR2, DDR3, DDR4 (Double Data Rate 2, 3, 4,5,6,7) — последовательные обновления DDR SDRAM, каждое из которых увеличивает пропускную способность памяти и снижает энергопотребление. Текущим стандартом является DDR4.
• DDR5 — это тип SDRAM (синхронной динамической памяти с произвольным доступом), который является технологией памяти следующего поколения. Он расшифровывается как Двойная скорость передачи данных 5-го поколения и является преемником памяти DDR4. DDR5 обеспечивает более высокую скорость передачи данных, больший объем памяти и повышенную энергоэффективность по сравнению с DDR4.Одним из основных улучшений DDR5 является увеличенная скорость передачи данных. Память DDR5 может обеспечивать скорость до 6400 МБИТ/с (мегатрансферов в секунду), что значительно выше максимальной скорости в 3200 МБИТ/с, предлагаемой DDR4. Увеличенная скорость передачи данных обеспечивает более быструю обработку данных и повышает общую производительность системы.
DDR5 также обеспечивает больший объем памяти по сравнению с DDR4. В то время как максимальный объем модулей DDR4 обычно составляет 16 или 32 ГБ на модуль, модули DDR5 могут поддерживать до 128 ГБ на модуль. Такая увеличенная емкость особенно полезна для задач с интенсивным использованием памяти, таких как игры, редактирование видео и анализ данных. С точки зрения энергоэффективности, DDR5 включает в себя новые функции.�� 18 июля 2023 года Samsung анонсировала первое поколение GDDR7, которое может достигать скорости до 32 Гбит/с на контакт (пропускная способность на контакт выше на 33% по сравнению с 24 Гбит/с на контакт у GDDR6), пропускная способность выше на 40% (1,5 ТБ/с) по сравнению с GDDR6 (1,1 ТБ/с) и на 20% более энергоэффективен. GDDR7 SDRAM (Graphics Double Data Rate 7 Synchronous Dynamic Random-Access Memory) — это тип памяти, обычно используемый в графических процессорах (GPU). Он является преемником GDDR6 и обеспечивает более высокую скорость передачи данных. GDDR7 предназначен для обеспечения доступа к памяти с высокой пропускной способностью для приложений с интенсивной графикой, что позволяет повысить производительность игр, увеличить разрешение и ускорить загрузку сложной графики. Он отличается более высокой тактовой частотой и улучшенной энергоэффективностью по сравнению с предыдущими поколениями. Модули памяти GDDR7 обычно имеют более высокую емкость и используются в графических процессорах высокого класса, используемых в игровых консолях, ПК и других устройствах, требующих интенсивной обработки графики. К сожалению, данный вид памяти пока не представлен на рынке, выпуск запланирован на первую половину 2024 года.
За консультацией обращайтесь к специалистам 2BService.
- по телефону +7 (495) 787-56-15;
- по электронной почте info@2bservice.ru;
- оставить электронную заявку на сайте.
Получить бесплатную консультацию и предварительный расчет стоимости